Optimizing Actions
Optimizing Actions is crucial for harnessing the full potential of Large Language Models (LLMs). Klu provides an easy way to fine-tune these Actions based on your specific needs.
This guide offers a comprehensive look at LLM optimization techniques, from basic to advanced strategies. Each section includes practical examples and resources for a hands-on understanding of these methods. Whether you're a beginner or seeking to expand your knowledge, this guide provides essential insights for effective LLM optimization.
Feedback
User feedback is essential for refining your Actions. We suggest collecting feedback through your app using the Klu API or SDKs, or directly in Klu Studio.
In the Data section of Klu Studio, you'll find rating icons for each data point. These icons represent Human Feedback, which Klu utilizes to identify quality generations and to enhance model training or fine-tuning for improved outputs.
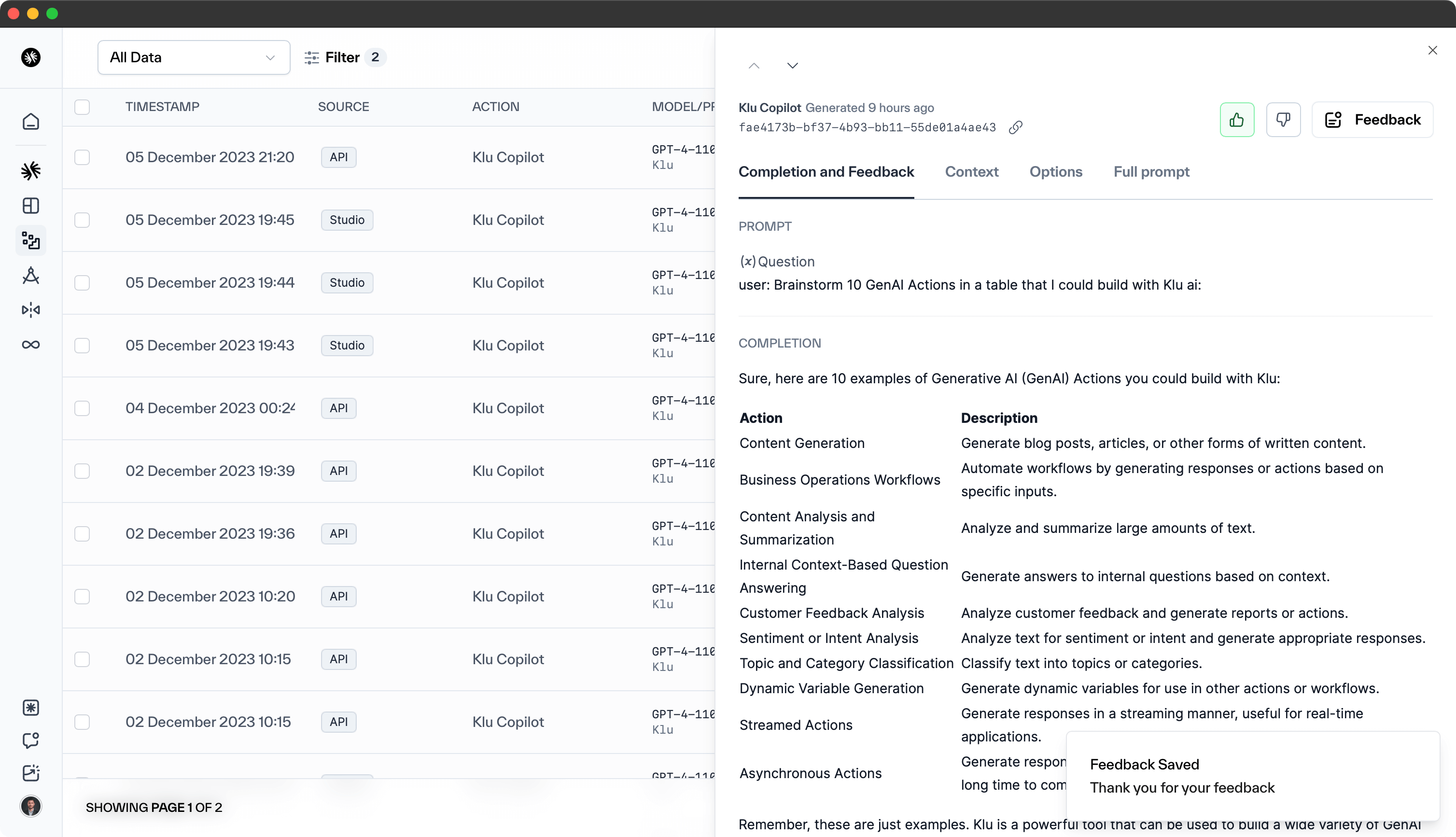
Click on the meatball menu next to any data point to access additional Feedback options including: setting use behavior, flagging generating issues, or setting a correction for a data point.

Within that modal you have various feedback options:
User Behavior- set a user behavior, including Saved, Copied, Shared, or Deleted.Generation Issue- set a generation issue, including Hallucination, Inappropriate, or Repetition.Response Correction- set a correction based on the completion output for a data point.
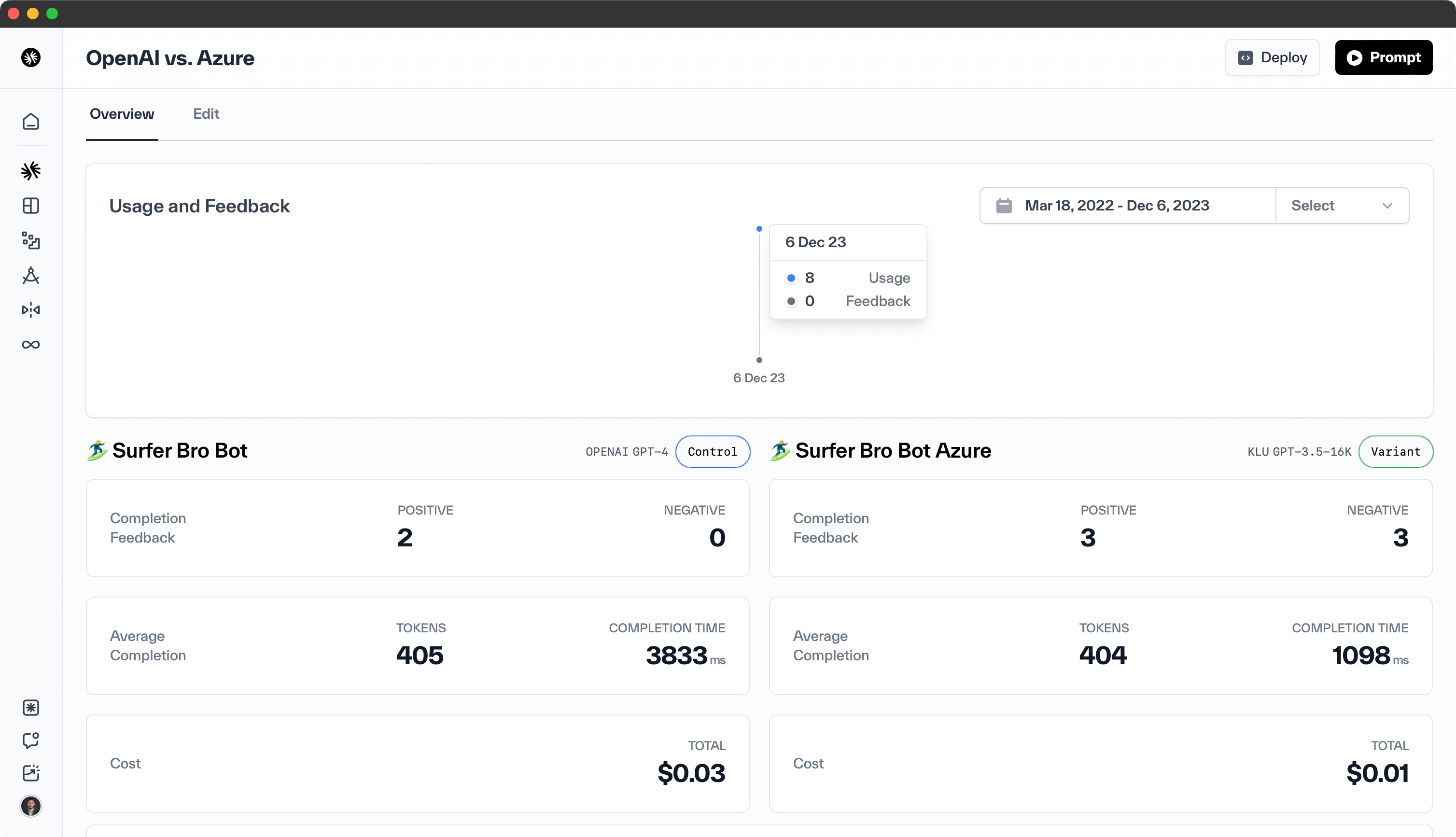
A/B Experiments
Klu enables you to conduct side-by-side comparisons of two Actions, ideal for evaluating different prompts or models. To create A/B Experiments, navigate to the Optimization section, select the "A/B Testing" tab, and click the Add Experiment button.

Select the Actions you want to compare in the Experiment and then you're ready! Once the data starts filling up you can compare both the user feedback and system data (tokens, time, etc.)
Fine-tuning
Fine-tuning enables you to customize an OpenAI base model with your own data. This technique enhances the quality of unique task outputs and can adapt the writing style to echo your brand's voice. It's advisable to leverage this feature after accumulating substantial data and providing feedback on the outputs.
We recommend the following minimums:
Style Transfer— 20-100 examples for transferring brand voice and writing styleFamiliar Task— 100-1000 examples for a familiar task like generating JSON objectsNew Task— 1000-2000 examples for a new task like executing a trust and safety policy
Fine-tuning LLMs refines their ability to comprehend human instructions, thereby enhancing the consistency of high-quality outputs. This process is particularly beneficial for tasks such as crafting emails in your brand's voice, generating JSON outputs for your app, or executing unique tasks like implementing a trust and safety policy.
We suggest conducting several experiments to determine the ideal number of examples tailored to your needs. To do this, execute an Action in a live environment and collect feedback on the results. This feedback will serve as the training data for fine-tuning. Navigate to the Data section, apply filters to select the datapoints for fine-tuning, and save this filter as a Dataset whenever necessary.
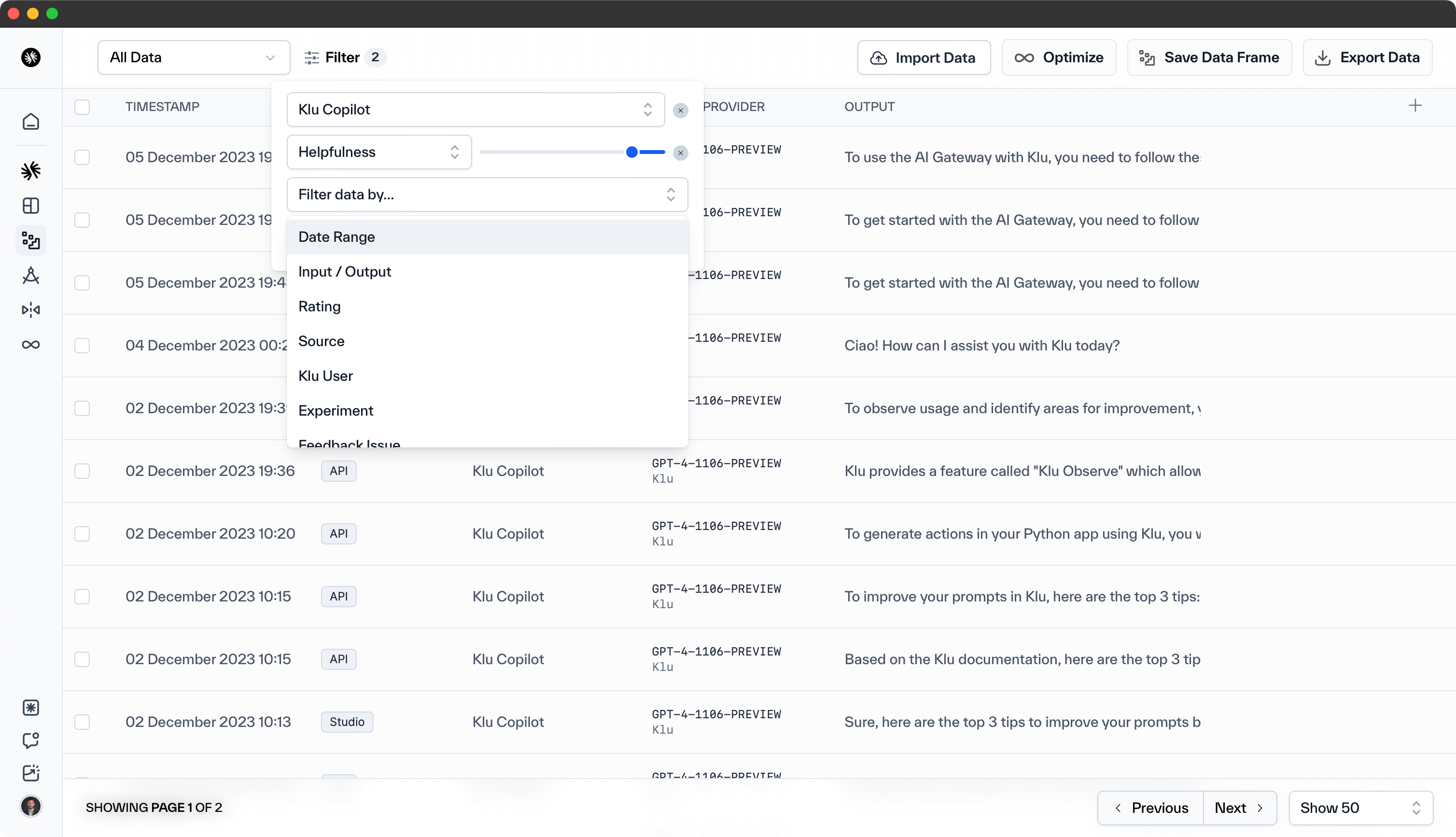
Filter to your preferred data points, save to a Dataset, and click on Optimize. Give the fine-tuned model a name, select your base model, and click "Optimize Model."
You will have to wait a few minutes to complete, but once it is done, you will be able to find your model in the dropdown list of models. The name of your model will look like this:
{base_model}:ft:{the name you gave it in klu}-datetime
You can use this model anywhere in Klu - either in the Playground or in Actions.